This is the first article in an introductory series about compilation, linking, and runtime libraries. I strongly suggest you start here unless you’re comfortable with these concepts.
The second article shows a real-world case study where a missing compiler runtime symbol caused a 6x performance regression in a key journey heavily reliant on Python’s
decimalmodule.The final article explore what are compiler low-level runtime libraries and when they’re used by referring to the missing symbol in the case study:
__udivti3.
My case study on fixing a symbol error in the Python interpreter shows how hard but impactful these problems can be: a subtle bug in how we build the C decimal library led to a key journey being 6x slower.
The fix was just one line in the build file to mitigate the unassuming error symbol not found error:
deps = ["@//cc/clang:compiler-rt_builtins"]
In this post I want to attempt building that context and sharing a methodology for how you can approach it. I’ll explain the concepts using C because it’s arguably the most influential programming language, but the general principles can be applied to any.
What is C?
C is a programming language. As such, C is used in C code like:
| |
Which can be compiled with a C compiler like gcc into an executable and run by a computer.
An exacutable is a type of binary file that can be loaded and executed by a machine. Some of the common characteristics of executable files are:
- A defined entrypoint, which is what the machine starts executing when the program starts
- No unresolved symbols (this will be explained later)
- Metadata for how to execute the program
| |
Yet like any language, C is defined by a specification. In C’s case it’s ISO C, which also defines the standard libraries. For example, printf is defined by ISO C in English like this:

The standard library implementations — such as stdio — are separate from the language itself. The two most common implementations are:
glibc, which emphasizes feature-richness and GNU compatibilitymusl, which emphasizes POSIX correctness and simplicity
For example, system is a C standard library function and the POSIX standard doesn’t require system to be thread-safe. glibc implements system with thread-safety as a nice-to-have, while musl doesn’t to be strict to the standard.
Thus, if you look at the glibc and musl source code you’ll find many overlapping function signatures but different implementations.
UNIX is an operating system started by AT&T in 1969. It created many copy-cat operating systems which made application development difficult because the underlying system calls weren’t the same.
The most widely used UNIX-like operating systems today are Linux (or GNU/Linux if you insist) and macOS.
POSIX, or Portable Operating System Interface, is a set of standard UNIX-based operating system interfaces to make it easier to write applications for UNIX-like systems. The standardization of many operating system function signatures makes applications more portable across POSIX-compliant operating systems.
The C compilation process
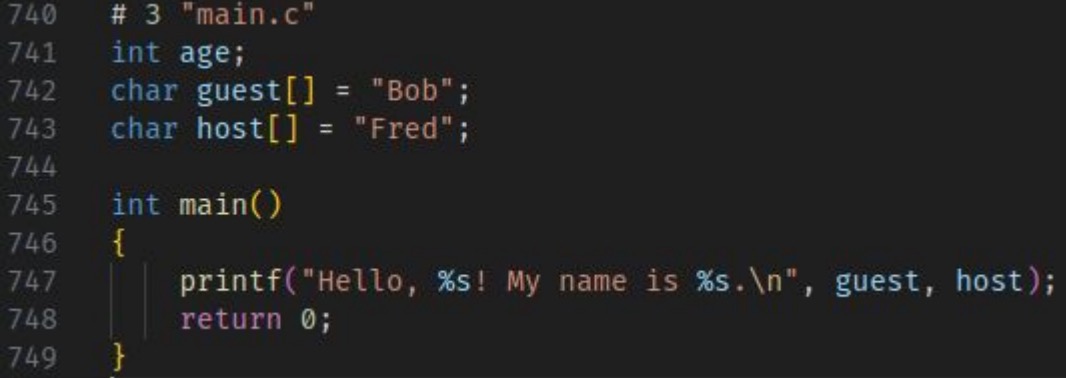
We’ll examine this hello world program through each stage of the compilation process.
| |
You’re probably thinking I’m using variables in a gross way. You’re right! This is on purpose because it’ll help us explore the different sections in binary file formats like ELF.
Object files are only aware of global variables because they’re initialized at compile-time, not local variables initialized at runtime — that’s why you’ll never find symbols for local variables in executable or object files. Thus, having global variables allows us to see them in a binary’s symbol table
Preprocessing
The first stage is preprocessing. The preprocessor takes a .c as an input, extends its source code, and output and intermediary .i file type that’s extended C code.
This file’s very different because if you look at it you’ll notice many function signatures of C standard library functions.

Our source code is only at the very end, like we wrote it.
Compilation
The assembly stage takes the .i C file and outputs an assembly .s file. If you haven’t looked at assembly before, it’s a symbolic representation of machine instructions.
For example, 1 + 1 might look like:
| |
Instead of:
B8 01 00 00 00 ; mov eax, 1
83 C0 01 ; add eax, 1
Assembling
The assembly stage takes the .s assembly file and outputs a .o object file. The difference is that you can use utilities to examine binary files and their symbols, which is very useful to understand how code maps to binary and how a machine executes it.
Think of symbols as name-value associations for functions and variables. The name is the function or variable’s name, and the value is the memory location of the function’s code or the variable’s value.
For example, the above program has a symbol table of only 5 symbols:
0000000000000000 B age
0000000000000000 D guest
0000000000000004 D host
0000000000000000 T main
U printf
The functions and variables from the C standard library in the
.ifile aren’t in the symbol table because thoseexternreferences just declare “this has been defined elsewhere”.Thus, the symbol itself is found in the binary where they’re defined — hence why this object file only has 5 symbols and not more.
Each column in the table represents a different type of value
- The memory location of the symbol’s value on a per section basis
- The section of the binary file the symbol’s in (e.g.
.data,.text, etc) - The name of the symbol
This is where the weird variable setup comes in play to show different section in a binary file:
B(or.bss) has uninitialized read-write data, andagewas defined without a valueD(.data) has initialized read-write data, i.e. initialized variables likeguestandhostT(.text) has executable-only data, i.e. code likemainUhas undefined symbols likeprintf(because it’s defined in a different object file)
Symbols are organized into different sections in a binary file. These change slightly according to the binary format, which is operating system-specific. For example, Linux’s is ELF and MacOS’ is Mach-O.
As you might’ve noticed above, the byte value for a symbol’s location is section-dependent in object files. Thus, the first symbol in a section will always be in byte 0.
Linking
So far we’ve gone from a file in C that prints values to stdout to an object file. However, there’s many reasons we can’t just run it:
- We have an unreferenced symbol in
printf - We don’t have an entrypoint that the operating system Loader can use to start the program
- The memory addresses in our object file are relative: we still need to relocate symbols to their actual memory locations where the code and data will reside at runtime
Broadly speaking, this is what we’ll providing in this final linking phase.
Linking is the process of combining multiple object files into an executable that the operating system can load and run. The linker resolves symbol references, performs relocations to establish final memory addresses, and adds necessary runtime metadata like the program entry point and dynamic linking information.
When we finish the compilation process of the program we started with we get the following symbol table. This is a lot, so we’ll break it down into the most important pieces.
000000000000038c r abi_tag
0000000000004020 B age
0000000000004019 B _bss_start
000000000000401c b completed.0
w _cxa_finalize@GLIBC_2.2.5
0000000000004000 D _data_start
0000000000004000 W data_start
0000000000001090 t deregister_tm_clones
0000000000001100 t _do_global_dtors_aux
00000000000003dc0 d _do_global_dtors_aux_fini_array_entry
0000000000004008 D _dso_handle
00000000000003dc8 d _DYNAMIC
0000000000004019 D _edata
0000000000004028 B _end
0000000000001180 T _fini
0000000000001140 t frame_dummy
00000000000003db8 d _frame_dummy_init_array_entry
0000000000002100 r _FRAME_END_
00000000000003fb8 d _GLOBAL_OFFSET_TABLE_
w _gmon_start
0000000000002020 r _GNU_EH_FRAME_HDR
0000000000004010 D guest
0000000000004014 D host
0000000000001000 T _init
0000000000002000 R _IO_stdin_used
w _ITM_deregisterTMCloneTable
w _ITM_registerTMCloneTable
U _libc_start_main@GLIBC_2.34
0000000000001149 T main
U printf@GLIBC_2.2.5
00000000000010c0 t register_tm_clones
0000000000001060 T _start
0000000000004020 D _TMC_END_
Symbol relocation
The first thing to note is that our 5 symbols are still referenced.
...
0000000000004020 B age
...
0000000000004010 D guest
0000000000004014 D host
...
0000000000001149 T main
U printf@GLIBC_2.2.5
...
However, the byte values are different because the symbols have been relocated to their final memory addresses. This is important because the program needs absolute addresses to reference its code and data at runtime. Without relocation, instructions wouldn’t know where to find their operands in memory or which addresses to jump to when calling functions.
As part of the symbol resolution and relocation, the linker also adds symbols to mark the boundaries of the sections as shown below.
0000000000004019 B _bss_start
...
0000000000004000 D _data_start
...
0000000000004019 D _edata
...
Dynamic linking infrastructure
Since this binary is dynamically linked, The linker also adds symbols so that we can dynamically link printf (which is still unresovled) at runtime.
...
w _cxa_finalize@GLIBC_2.2.5
...
0000000000004008 D _dso_handle
...
00000000000003dc8 d _DYNAMIC
...
00000000000003fb8 d _GLOBAL_OFFSET_TABLE_
...
U _libc_start_main@GLIBC_2.34
...
U printf@GLIBC_2.2.5
We’ll gloss over this and come back to dynamic linking later.
Runtime metadata
Based on what we’ve seen so far we still need something to help the operating system and runtime environment manage the program’s execution. They come from the C runtime object files (i.e. crt0.o, crti.o, and crtn.o).
Some of these come from the C runtime object files, which manage the entry point to the program (_start) and the program’s initialization (_init) and finalization (_fini).
| |
These are important because:
_startis the first thing executed in the program_initruns beforemainand sets up the runtime environment_finiruns aftermainand runs cleanup tasks
Dynamic linking at runtime
By this point we have an executable with an entrypoint that is expecting the dynamic linker to provide the final symbol references that it needs.
...
U _libc_start_main@GLIBC_2.34
...
U printf@GLIBC_2.2.5
...
What the dynamic linker does is to try to load the .so shared object file from the file system from a series of paths (which you can find by using ldd on an executable). This happens at runtime when the executable is loaded into memory, not at compile time.
A methodology for linking errors
Is it even a linking error?
As I hope you’ve gotten from going through how compilation works, programs are collections of symbols. The symbols include the source code of the programs plus functions and variables needed to manage the program’s runtime and link it.
Thus, you’ll have linking problems when your executable either
- Can’t be built because of a missing symbol
- Builds but has a runtime error because of a missing symbol
If it’s a linking error you’ll see errors such as (but not limited to) undefined reference, symbol not found, or multiple definition of.
Find the guilty symbols
If it is a linking error, it’s probably related to a missing or redundant symbol. This means you’ll need to find the guilty symbol and either link the missing .so at runtime or remove the duplicate symbol.
For the purposes of time I won’t get into details, but you should look at using these tools or the equivalent for your operating system:
- List dynamic dependencies to list the shared objects being linked to your binary (
ldd) - Symbol inspection to verify if the shared object has the symbol you’re looking for (
nmandobjdumpif you need more functionality) - Check the paths referenced by the dynamic linker (see an excellent guide here)
Closing remarks
Tools like ldd and nm help a ton. I really would not like to solve a linking problem without them!
However, as I showed in my linking case study on the Python interpreter there are some problems where you just need the knowledge and context: ldd won’t point you to a low-level compiler runtime library or the C runtime. Hopefully, this article is a primer on how to think about these problems and, more broadly, how to think about what programs are and how they compile.
Further reading
If you want to continue learning about compilation and linking, I highly recommend:
- Computer Systems: An Application Programmer’s Perspective is great at building up the necessary context and introduces linking in chapter 7
- Beginner’s Guide to Linkers
- Ian Lance Taylor’s 20 part blog post on linkers